Το Google Docs υποστηρίζει OCR και στα ελληνικά, αλλά είναι μέτριο
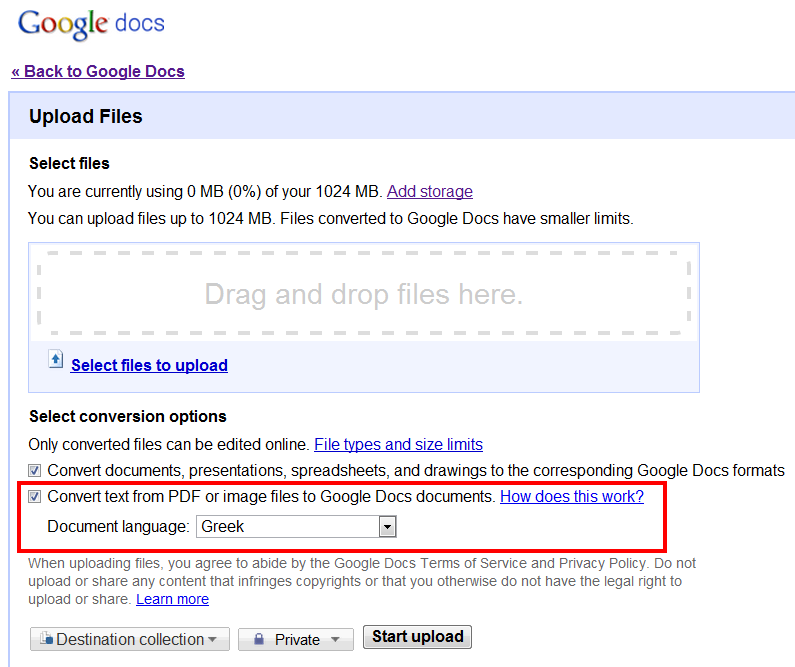
Το Google Docs υποστηρίζει από χτες τη μετατροπή αρχείων PDF εικόνας και άλλως αρχείων εικόνας σε κείμενο και για τα ελληνικά, ανάμεσα σε 34 άλλες γλώσσες. Η πρώτη δοκιμή μας έδωσε ένα πολύ μέτριο αποτέλεσμα, ενώ η υπηρεσία έχει περιορισμό στο μέγεθος του αρχείου που μπορούμε να ανεβάσουμε.
Τα αρχεία εικόνας μπορεί να είναι ένας γρήγορος τρόπος να σκανάρουμε ένα κείμενο ή να πάρουμε με το κινητό μας τηλέφωνο φωτογραφία του κειμένου που μας ενδιαφέρει, αλλά δεν επιτρέπουν την αναζήτηση μέσα στο κείμενο, δε μετατρέπονται σε αρχεία ePUB και Mobi για ηλεκτρονικούς αναγνώστες, tablet PC και κινητά και, τέλος, δεν μπορούμε να επεξεργαστούμε το περιεχόμενό τους. Το Google Docs επέκτεινε τη δωρεάν υπηρεσία OCR (Optical Character Recognition, “οπτική αναγνώριση χαρακτήρων”) για τη μετατροπή αρχείων εικόνας σε κείμενο και στα ελληνικά.

To κάθε αρχείο που ανεβάζουμε για μετατροπή δεν μπορούν να είναι μεγαλύτερα από 2MB (πολλά PDF είναι μεγαλύτερα) και στη δωρεάν εκδοχή της υπηρεσίας τα αρχεία που μπορούμε να ανεβάσουμε συνολικά δεν μπορούν να καταλαμβάνουν αποθηκευτικό χώρο μεγαλύτερο από 1024MB. Το κυριότερο πρόβλημα είναι όμως, ότι όπως βλέπετε στο screenshot, το κείμενο που προκύπτει δεν είναι ιδιαίτερα αναγνώσιμο και θέλει πολύ επεξεργασία. Προς το παρόν δηλαδή, το Abbyy Fine Reader μετατρέπει εικόνες σε κείμενα στα ελληνικά πολύ πιο αποτελεσματικά.
- Πόσα βιβλία υπάρχουν στον κόσμο; 129.864.880 απαντάει το Google Books
- Ξεκίνησε η λειτουργία του Google ebookstore (πρώην Google Editions)
- Google Books Preview για τον Chrome, το extension για άμεση πρόσβαση στο Google Books
- Google Books Ngram Viewer, στατιστικά για τη γλώσσα και την κουλτούρα μέσα από εκατομμύρια βιβλία του Google Books
- Η Google αγόρασε την eBook Technologies – τι ετοιμάζει;
- Παρουσιάστηκε επίσημα το Android 3.0 Honeycomb και το Android Market Webstore
- Πώς θα διαβάζουμε Google Books στο Android 3.0
- Μερικές ενδιαφέρουσες ειδήσεις από το live webcast για τα Google ebooks
- Ολόκληρο το webcast και η παρουσίαση για τα Google ebooks
- Ιστορίες από τους χρήστες του Google Books (video)
- Τα ebooks της Google στο Android Market, αλλά μόνο για τις ΗΠΑ